
To understand about Hadoop, we need to have an idea about Big Data and Big Data Analytics.
Row data has no value. It only becomes valuable on getting processed to produce results, where these results can give insights in taking the right decisions for implementing the most suitable actions, to achieve success. Today’s technical advancements have made available a vast amount of structured/unstructured data, which can be analyzed/processed using tools (like Apache Hadoop, Microsoft HDInsight, NoSQL, Hive, etc.), to enable right decision making/finding solutions to problems.
To get a clearer understanding, have a look at our own blog on the topic ‘Big Data’ here: https://www.nodericks.com/buzzword-talk-big-data/
Big Data Analytics
Big data analytics is the process of examining big data to find out patterns, correlations, trends, preferences and other useful information to enable the right decision making. This will help in things like – finding solutions to problems, more streamlining, implementing suitable actions – to gain success. For this, big data analytics are driven by specialized softwares as well as analytic systems.
By enabling organizations to harness data and use this data to identify opportunities, big data analytics can help in implementing strategic business plans. This will result in operational efficiency, customer satisfaction and in turn, an increase in profit. Big data analytics achieve this through Cost Reduction (Big data technologies like Hadoop as well as Cloud-based analytics can store vast amounts of data, saving money.), Faster Decision Making (Super-fast analytics done by technologies like Hadoop, in-memory analytics, etc. enable speedy decision making.) as well as Production of New Products and Services (Analytics give a more precise understanding of customer preferences and needs, using which companies can make products and services which can precisely meet the customer requirements.).
Big Data Analytics Tools comes in two categories – Data storage tools, Querying / Analysis tools. Apache Hadoop, Microsoft HDInsight, NoSQL, Hive, Sqoop, PolyBase, BigData in EXCEL, Presto, etc. are examples of Big data analytics tools.
Here, let’s have an overview of Apache Hadoop.
Apache Hadoop
This big data analytics tool is a Java-based, open source software framework containing a collection of software utilities which can facilitate effective use of networked computing devices to do problem-solving involving big data. Hadoop is the foundation of all big data applications.
Components/modules of Apache Hadoop can be classified as,
- Hadoop Distributed File System (HDFS) – An enormously reliable storage system which allows data storage across multiple linked storage devices, in an easily accessible format. Storage layer.
- MapReduce – Distributed processing layer. Three operations are done here: Reading data from the database, Putting the data into a format suitable for analysis and Performing mathematical operations on the data. We can see its working from this simple diagram shown with an example –
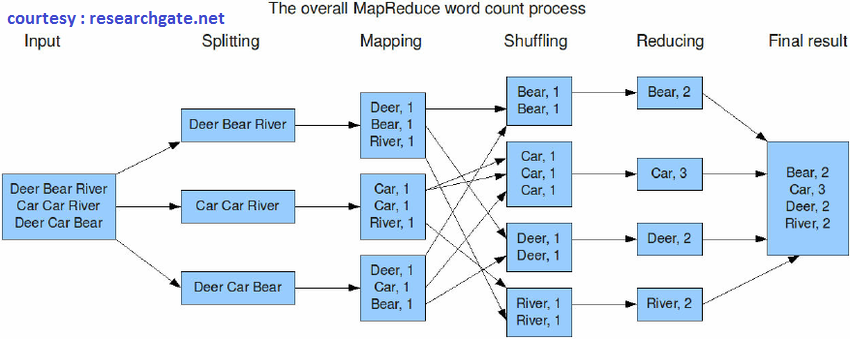
3. YARN (Yet Another Resource Negotiator ) – It is the resource management layer. Manages the data storage (HDFS) as well as the analyzing (MapReduce) resources of the system.
4. Hadoop Common – Collection of the standard utilities and libraries supporting the other three Hadoop modules. Hadoop Common provides the tools in Java for the user’s computing system (Windows/Unix/whichever platform), to read the data stored in the Hadoop File System.
All the above Hadoop modules assume that hardware failures are common and it should be automatically handled by the Hadoop Framework software. In Hadoop, data is stored in the distributed manner in HDFS across the cluster, making parallel data processing on a cluster of nodes, resulting in load balance.
Because of its ability to process complex data, flexibility to store and mine data irrespective of the fact that it is structured/ unstructured, as well as easiness in development (because it is written in Java), Apache Hadoop is today’s most popular big data analytics tool.